ontologies
2022 - Week 39
Two editions of weeknotes in two weeks! Truly miracles do happen.
All the right steps, not necessarily in the right order

Our regular reader - well, JO Jane at least - will be well aware of the issues we’ve had with step ordering on both the statutory instrument and treaty tracking websites. Whilst Parliament may be very good at reporting what happened on a day, at what time those things happened is more elusive. Both SI and treaty procedure regularly see a number of procedural steps happening on the same day. But with no timing information available, the website code has no clue what order they happened in and no clue how to order them for display. With nothing to go on and no clues given, our timeline pages have been - to be quite frank - risible, steps being ordered at random, in a fashion that matches neither procedural nor common sense. The example below - from the Abortion (Northern Ireland) Regulations 2022 - has the instrument being approved by the House of Lords, before the question on the approval motion is put, before the non-fatal amendment to the motion is rejected, before the question on the non-fatal amendment is put, before there’s even been a debate. Which is pretty much as topsy turvy as you could get.
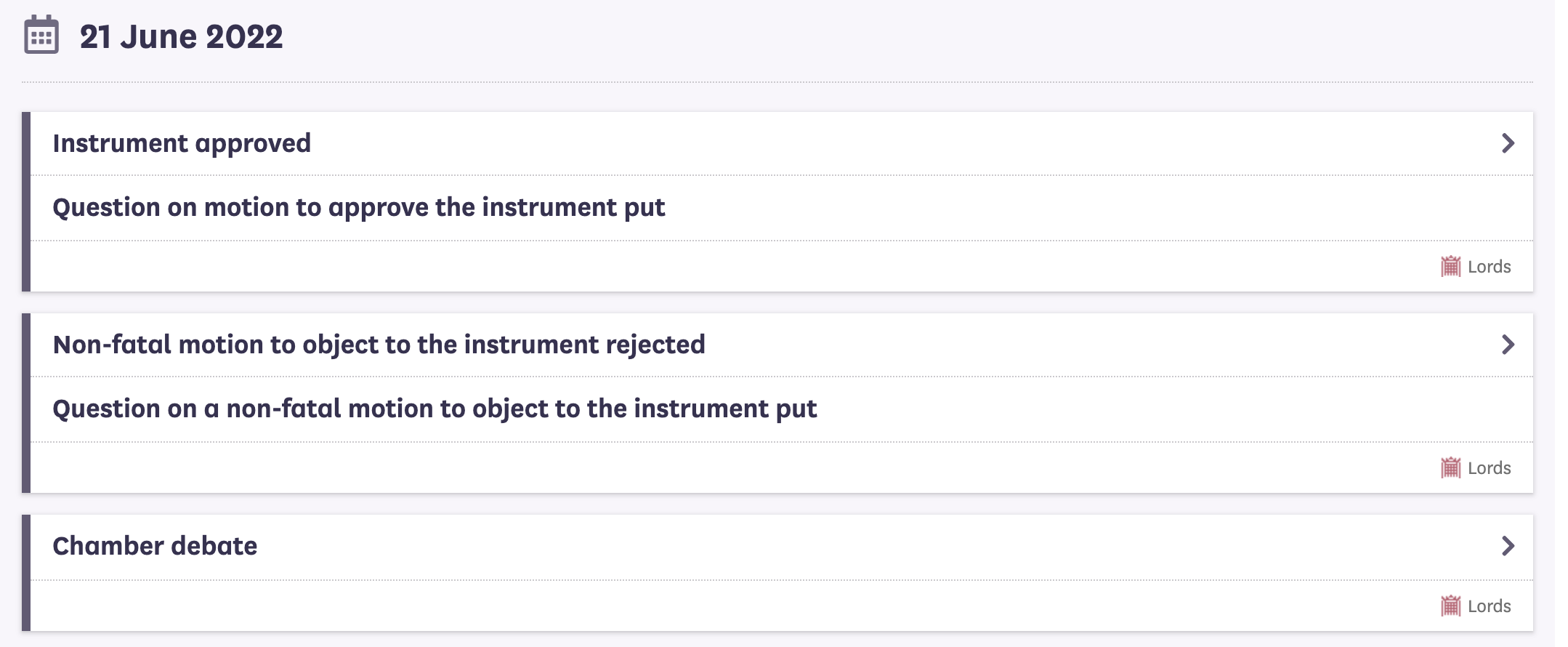
Early attempts to fix this problem saw us taking a mathematical approach and spanning the procedure map tree. But a graph is not a tree, so that didn’t work. In recent weeks, we changed tack, stopped treating the problem as some sums and started to treat it as yet more information management. Librarian Jayne and her computational handmaidens, Young Robert and Michael, added a new concept of step depth to our procedure model and procedure editor schema. Our Jianhan added new functionality to the procedure editor application, database and triple store. Jayne added step depths to both maps and data. Jianhan chipped back in with a new SPARQL query to order timelines through a combination of dates and step depths. Colleagues in Software Engineering deployed Jianhan’s new query and, following a wee bit of additional tinkering - quite a lot of additional tinkering to be honest - testing revealed the new model, data and query worked. Perfectly. Which means the timeline for the instrument mentioned above now has a debate taking place before the question on the non-fatal amendment is put, before the non-fatal amendment to the motion is rejected, before the question on the approval motion is put, before the approval motion is approved.
{kind=link}
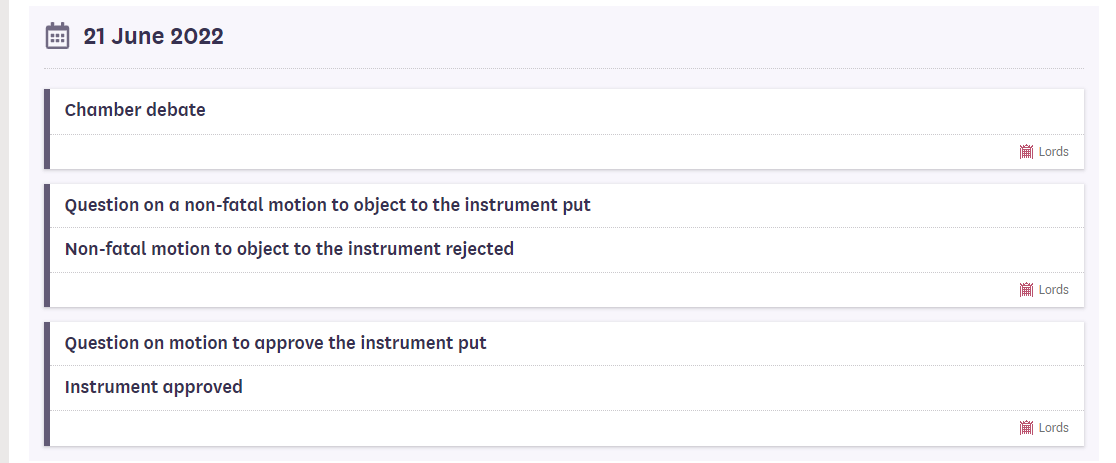
Much less ridiculous, as we’re sure you’ll agree. And yet more proof - as if proof were needed - that putting domain knowledge, modelling, mapping and information management in the same place is the only reasonable approach to making things with computers. It is at this point that we smile sweetly at JO Jane and suggest a pint. Whilst a pint can still be afforded.
Breaking egg timer news
If you tuned in last week, you’ll already know that Michael has been on a mission to protect his purse from further Heroku-induced costs. To that end, Jianhan and Robert were roped in, applying computational spanners to give Azure a firm thwacking. Librarian Jayne has now tested their efforts and declared herself happy. Which means our beloved egg timer has a new home:
If you happen to be an egg timing enthusiast, please update bookmarks and documentation accordingly. If you were subscribing to any of our sitting day calendars you’ll also need to update those subscriptions. At some point soon, Heroku will stop offering a free to use tier and, quite frankly, paying for compute in dollars has never looked less attractive. For that reason, the redirect from the old website will stop working on the 31st October 2022 so if bookmarks aren’t updated, you may well lose your egg timing capabilities forever.
Losing a librarian from the loop
Whilst saving Michael’s purse may be a worthwhile endeavour, no amount of pennies skimped will save on librarian labour. As we found to our cost with recent sitting day changes. The problem being we have our lovely procedure model in one place and our beloved egg timer in another. And the two systems are barely on speaking terms. Or at least they only whisper to each other via a librarian.
Our current workflow sees our crack team of librarians create a work package per instrument, add business items to said work package and actualise procedural steps with those business items. Whenever a clock is encountered, the duty librarian fires up the egg timer, plugs in the type of days to count, the number of days to count and the start date. The egg timer whirrs and provides the end date, which the librarian notes down before heading back to the procedure editor, creating a new business step actualising the clock end step and typing in the end date. Which is all well. And all good. At least until sitting days change, as sitting days are wont to do. At which point, whichever poor librarian has copped the short straw has to go into every instrument currently before Parliament and update every clock end step. Last time out, Librarian Martin picked up the shortest of straws and ended up updating clocks for over 100 instruments. Not a pleasant task.
All of which led Lead Librarian Anya to suggest - perhaps unsurprisingly, in a pub if memory serves correctly - that it may well be time to take our plan to integrate procedural data with egg timer calculations off the back burner. A suggestion that led to Librarians Anya and Jayne and computational pen-pusher Michael meeting in pixels on Friday afternoon and scribbling a sketch of what such an integration might look like. For now, it’s a hand-wavy, fag packet sketch but, as we’ve no doubt said before, if a model doesn’t fit on a fag packet, it probably can’t be built. Anything much larger than a fag packet teetering on the brink of enterprise architecture. Not a thing that sparks joy. We still have at least one outstanding question around whether a single procedure with multiple clocks might ever use different styles of calculation per clock. But with both JO Jane and Philipp taking much needed vacations, that’s more chummer for next week.
{kind=link}
Teaching the machines about legislative reform orders
Speaking of the JO twosome, Jayne, Ayesha and Michael spent part of Thursday in the very pleasant company of JO Jane and her hound Indiana Bones. JO Philipp was supposed to come along but unfortunately couldn’t make it. Packing his trunks we assume. The purpose of the meeting was a homework marking exercise, always a thing that brings JO Jane’s ex-teacher skills to the fore. Assorted legislative reform order maps were opened, steps described and routes traced. No gold stars were awarded but we think we got a pretty strong 8/10 for our efforts. That said, it looks more than likely that the maps may well need yet another damned clock. So we’re up to five now. You can see why Anya is keen to plumb in the egg timer.
A large and laborious part of the week saw Librarian Ayesha and her computational bedfellow Michael continuing with the long, slow grind of adding LRO procedure routes to the machines. The machine being good enough to spit out DOT files - and not hairballs - in return. There’s not much to show for their effort and, if there was, very few people would want to look. Still, it’s all progress.
On matters of consent
Thursday afternoon took on a slightly Sewel flavour as attentions turned to matters of consent in the context of devolution. First up, Jayne and Michael popped along to Devolved but denied? Regulations and consent beyond Westminster, an online event hosted by the Hansard Society. We’ve given quite a lot of thought and time to mapping legislative consent motions in the primary legislation context - weeknotes passim - but not so much in our more usual stomping ground of secondary legislation. Jayne made many notes. We may well need to act on them. Thanks be to Ruth and colleagues.
Not being the types to put our hands up in meetings - and chat being deactivated anyway - now might be a good time to mention that Jayne has cobbled together a couple of handy queries dealing with affirmative instruments under Section 10 of the United Kingdom Internal Market Act 2020. Which may well be of use to fans of devolution, and indeed consent.
Meeting two saw Jayne, Claire and Michael joined in pixels by the Northern Ireland Assembly’s very own Christine who kindly donated her time to idiot check our legislative consent motion map for the NIA. Once again no gold star, but again a pretty solid 8/10. That said, the addition of yet another new clock seems to be necessary. At this point, we are literally drowning in clocks. Thanks for the hook up Legislation Office Liam.
The third and final consent meeting of the afternoon saw a cast of crack librarians joined by the very same Legislation Office Liam and soon to be Legislation Office Tom. We have a longterm plan to map out the full public bill procedure but, when we say longterm, we really mean it. Given the complications and complexity it looks like we’ll be mapping until death or retirement. Whichever comes first. In the meantime, we have two and half fully mapped legislative consent motion procedures, done in collaboration with colleagues in the devolved legislatures. And when we next meet Christine in a week or two, we should have all three. We also have the work that our Jianhan’s doing to make our procedure model unicameral compliant. Which means we’re wondering if we can use the meantime to put the bits we do have to some use. A plan was planned to get something rough and ready in place to track LCMs by the far side of Christmas. As ever, it may all come to naught, but if you don’t research, you don’t develop.
Interests financial and otherwise
With Young Robert on vacation, modelling matters of an ontological nature climbed into the back seat and fell fast asleep. Michael continued his newly indentured life in the service of the Register of Members’ Financial Interests. In collaboration with Registrars Thomas and James, and in the company of Tom, we now have ‘as is’ models for nine of the ten Commons categories. One more meeting and a tad more fettling should put paid to phase one. It should be noted that ‘as is’ in this context does not mean documentation of the current data model. The current data model being pretty much a single string and some timestamps, there wouldn’t be much value in that. ‘As is’ here refers to a model that conforms to the current ruleset with the very tiniest hint of the tightening of spanners. How tight those spanners can tighten being the subject of another chat with Committee Clerk Stuart.
In the meantime, and as we said last week, we’re somewhat lacking in our competency questions. Or things the new system might be expected to be able to answer. Or at least we were. This week, Librarians Anna, Ayesha and Deanne have been casting keen eyes over written and oral evidence and decanting all bits pertinent to competency into a brand new spreadsheet. Top work librarians. And not just that. Steve has also been leafing through his rolodex, pulling out contacts and pinging them in search of more questions for more competencies. Which means our competency question Google doc is now full to bursting. Thanks Steve. Really helpful. Really really helpful.
Next steps involve politely asking our crack team of librarians to also index the competency questions provided by Steve. Then ?someone? has to sit down with the data models and work out which ones we might hope to be able to answer, which ones are ‘maybe’ and which ones definitely sit outside the bounds of the current ruleset. At first glance, it would appear many more may well end up in the last bucket than the first. But that is merely a first glance. We should know soon enough.
Finally dear reader, if you’re the kind of person who might take an interest in the RMFI - or you know someone who is - and would like to contribute, please do get in touch. We cannot, of course, promise to design a system that answers everyone’s questions, but the more we know, the better we’ll do.
On matters of information management
A couple of months ago - is it only that long? - our regular reader will recall we had our heads buried in our shiny new parliamentary paper model. Part of that model provides a polyhierarchical - we don’t mess around in these parts - taxonomy of paper types. What this taxonomy should contain being a matter for later. Well, later has arrived and we can put it off no longer. Anya, Jayne and Michael have put together a spreadsheet of candidate terms and hatched a plan. At some point, in a recess not too far off, we hope to get our crack team of librarians rifling through old papers, attempting to index them and seeing which candidate terms work, which don’t and what’s missing.
Until next time ….